AI知识库搭建初探:Anything-llm的实践与效果分析
我当前的工作中缺乏系统的知识沉淀,知识以碎片的形式分散在不同的地方,检索起来非常的麻烦,给业务模块开发和维护带来很大的障碍。我计划搭建一个知识库,来缓解这个问题,其中的难点主要在于如何持续更新维护知识,以及如何快速从其中检索信息。
知识主要来源主要包括人工系统的梳理记录,文档平台中的资料、代码提交日志、需求交互文档等。完成知识库搭建之后,我期望能够借助AI技术,解决快速检索信息的问题,提升工作效率。
为了快速且低成本地实现检索这一目标,我在网上寻找了能够构建AI知识库的工具。我发现了Anything-llm,一个在GitHub上拥有12.2k星标的开源RAG框架,它专为快速搭建AI知识库而设计。
Anything-llm的安装过程极为简单,通过Docker即可轻松部署。它内置了向量数据库LanceDB和embedding模型,只需接入大语言模型,即可开始工作。按照官方文档(HOW_TO_USE_DOCKER)的指导,使用docker镜像,几分钟内即可完成部署。
在部署过程中,可能会遇到一些失败的情况,如配置文件所在文件夹权限不足导致的大模型配置文件存储和数据库文件创建失败。通过docker logs containerName命令 查看日志即可发现问题所在,并通过修改文件夹权限解决。
部署完成后,使用浏览器访问网页地址进行配置,配置过程仅需指定LLM API地址,其他选项均使用默认配置。在配置过程中,需要指定2个LLM模型,一个是Chat模型,另一个是Embedding模型。Chat模型我选择使用本地qwen 7b模型,通过 Ollama 提供API,Embedding模型使用内置的模型AnythingLLM Embedder。其中Chat模型的作用是使用知识库中查询到的关联文本块内容,进行理解和回答。
一切准备就绪,马上开始创建创建Workspace,即知识库,我使用我的数字花园的内容进行测试。在知识库的上传文档的面板中,我们可以上传文件并进行向量化处理,从而完成知识库的搭建。
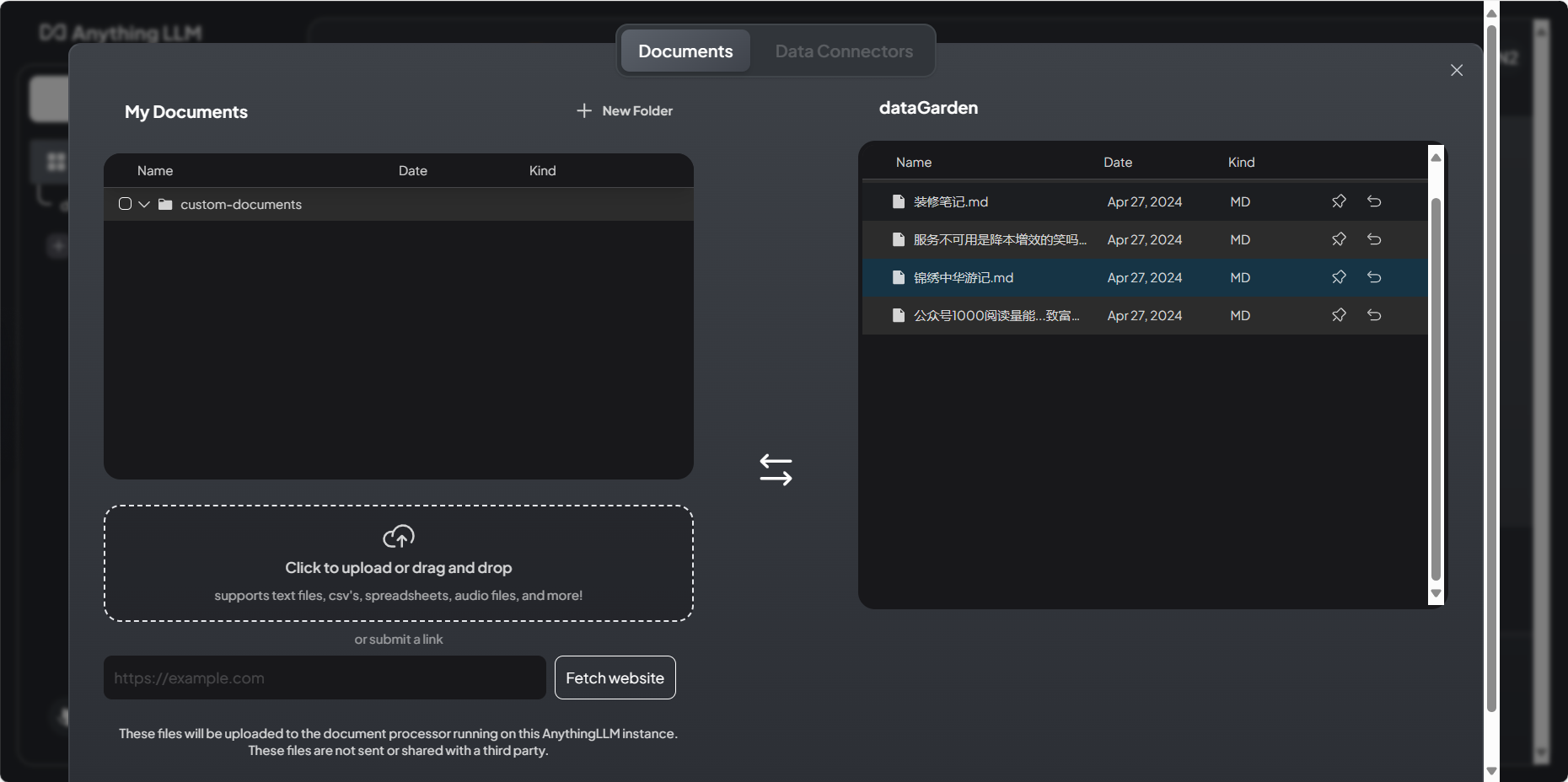
创建Workspace,上传文档,添加到工作空间,并点击Save and Embed
上传的文档Embed完毕,开始提问。经过试用发现Anything-llm的查询效果并不理想。使用qwen 7b 4bit量化模型,并针对性地提出了9个问题。尽管这些问题在相关文章中都有对应的关键字提及,但Anything-llm只准确回答了1个问题,提到了相关信息的有1个,2问题回答在上下文中未找到相关信息,而剩下5个则使用了知识库中不存在的内容进行回答。总的来说只有22%的准确率,远未达到预期。
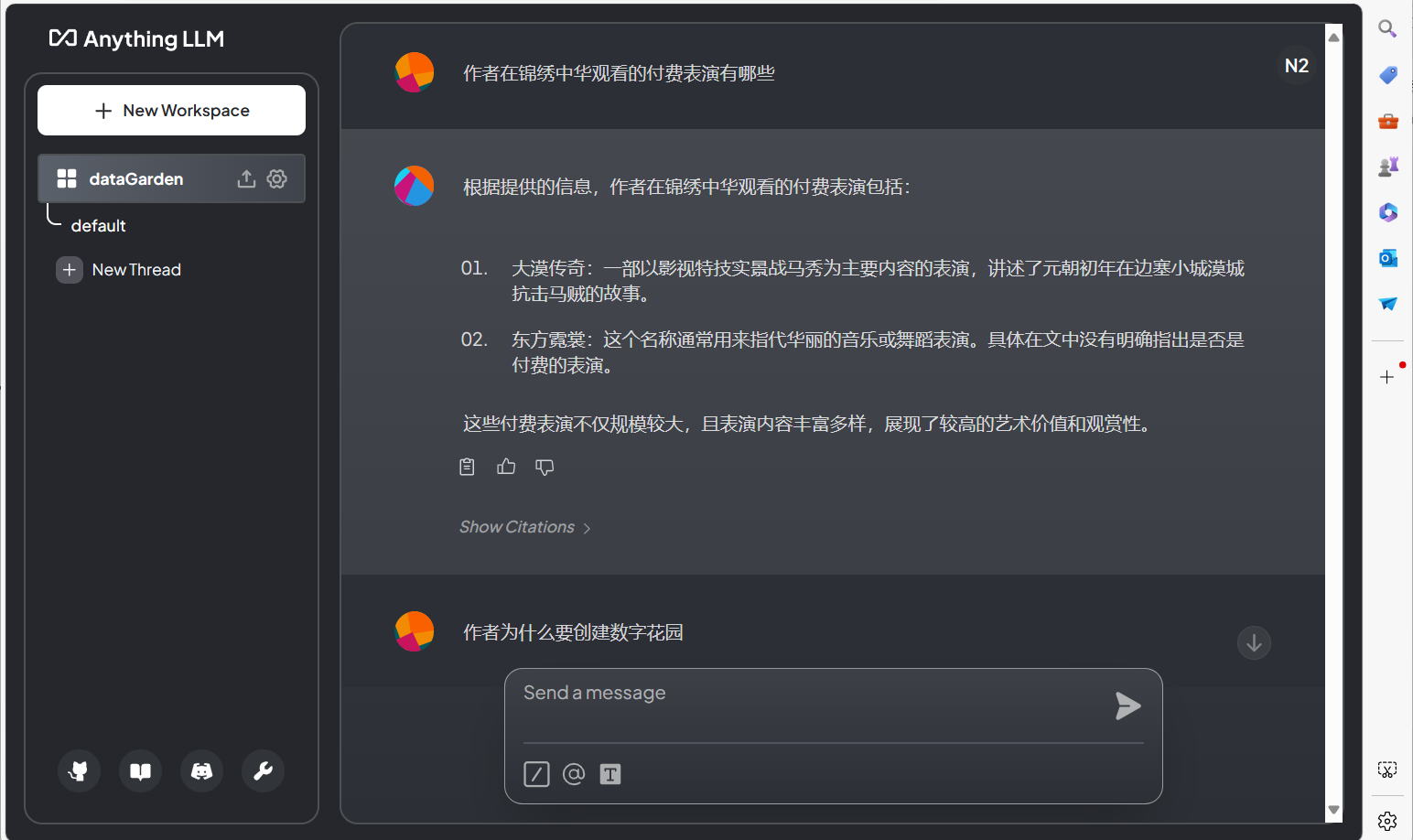
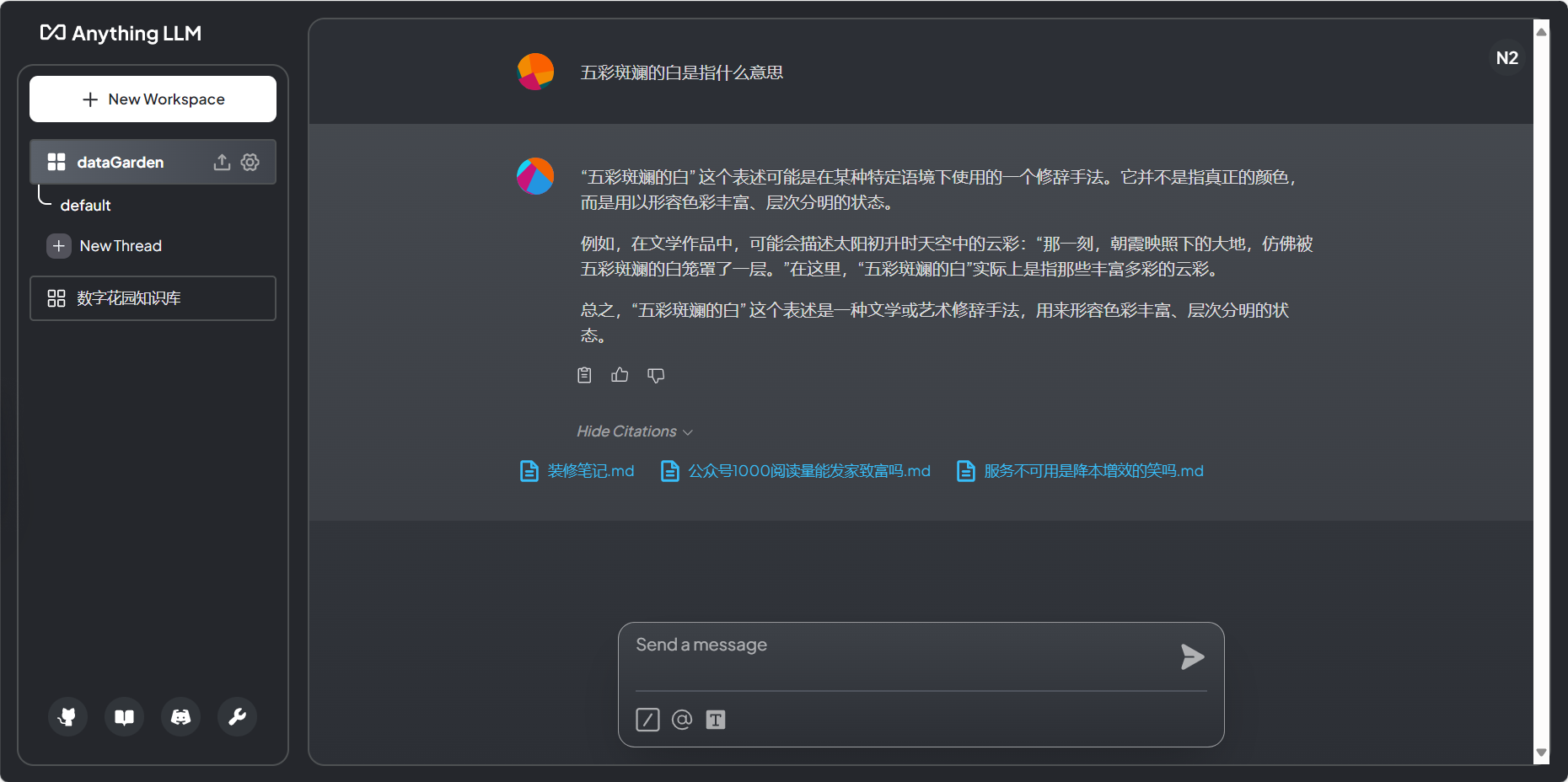
为什么准确率这么低呢?点击回答下面的 Show Citations,查看查询到的关联文档。点击文档查看匹配到的文本片段,发现文档中真正关联的内容并未包含,更扯的是毫无关联的文档匹配度反而最高!
虽然Anything-llm在部署和使用上非常便捷,数据文件向量化也实现了自动化,无需人工参与,界面和交互流程也相对友好,但其准确率低的问题非常突出。输入的问题查询到的关联文本的匹配率非常低,可能是由于embedding模型选择不当、或者知识库文档拆分方式不够合理导致的。
Anything-llm是一个RAG应用,RAG的关键点在于检索查询。检索查询关联内容有非常多的方式,并不一定要使用embbing,最基础的关键字检索也是一种方式。文本的拆分和分块(Text splitting & Chunking)是embedding关键的点,文本分割也有非常多的方式,比如Anything-llm根据文本长度对文档进行拆分。
为了提升Anything-llm的实用价值,可以从embedding模型选择、文档的拆分方式入手,进一步提升查询效果。在未来的探索中,我可能尝试对其进行更深入的优化和研究,以期带来更好的实际应用效果。
总结Anything-llm初探:
- 支持通过API指定LLM,支持Ollama
- 安装使用流程简单,自动化程度高
- 文本只能根据长度分割,不能指定其他方式,不能对分段进行查看和维护
- 对文档查询效果(召回)进行调试
知识库创建与使用完整流程视频。
![[anthingllm.mp4]]
相关链接:
- 基于Ollama+AnythingLLM快速搭建本地RAG系统 - 知乎 (zhihu.com)
- AnythingLLM | The ultimate AI business intelligence tool (useanything.com)
- BUG: Failed to save LLM settings · Issue #654 · Mintplex-Labs/anything-llm (github.com)
- SQLite database error · Issue #426 · Mintplex-Labs/anything-llm (github.com)