Ollama个人电脑运行大模型效果实测
当前有许多免费的大语言模型可供我们使用,包括不久前GPT 3.5开放了免费使用,但这并不意味着它们将永远免费。特别是当通过API接口调用模型时,一旦使用量增加,费用会相当可观。
本地部署大模型是让我非常兴奋的事。通过这种方式,深入学习研究大模型,探索能给我们带来价值的应用场景,构建自己的AI应用,而且在这个过程中无需为token数量烦恼!

简介
Ollama 是一款帮助我们快速在本地运行开源大模型的工具,主要有以下特点。
- 基于 llama.cpp 开发,提供GPU、CPU运行能力,当显存不足时,能够很哇塞的使用GPU+CPU运行
- 使用非常简单,提供跨平台的命令行界面,支持大模型的拉取、部署、运行
- 提供web API,无缝对接各种工具和客户端,如 chatbox、open-webui、Anything-llm 等可以对接
- 提供Python、Js库,方便集成到个人应用程序
模型
Ollama 维护了一个常用的模型仓库 library (ollama.com),通过ollama pull 模型 命令可以方便的拉取模型,拉取速度很快,无需翻墙!
Ollama 主要提供量化模型,默认拉取4bit模型,也可以自行指定。对于仓库中没有的模型,支持导入 GGUF 模型文件,GGUF 可从hugging face下载,如果没有提供该格式的文件,可以使用工具进行转换。
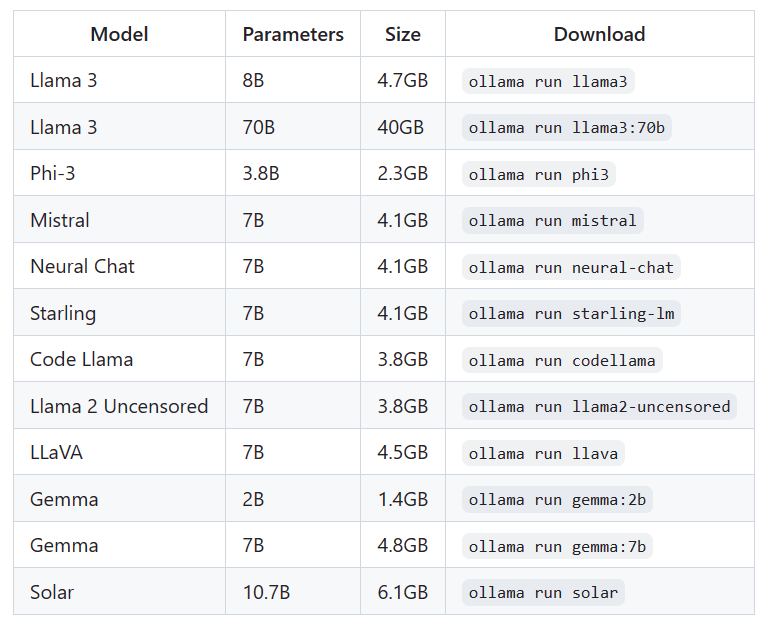
常见模型
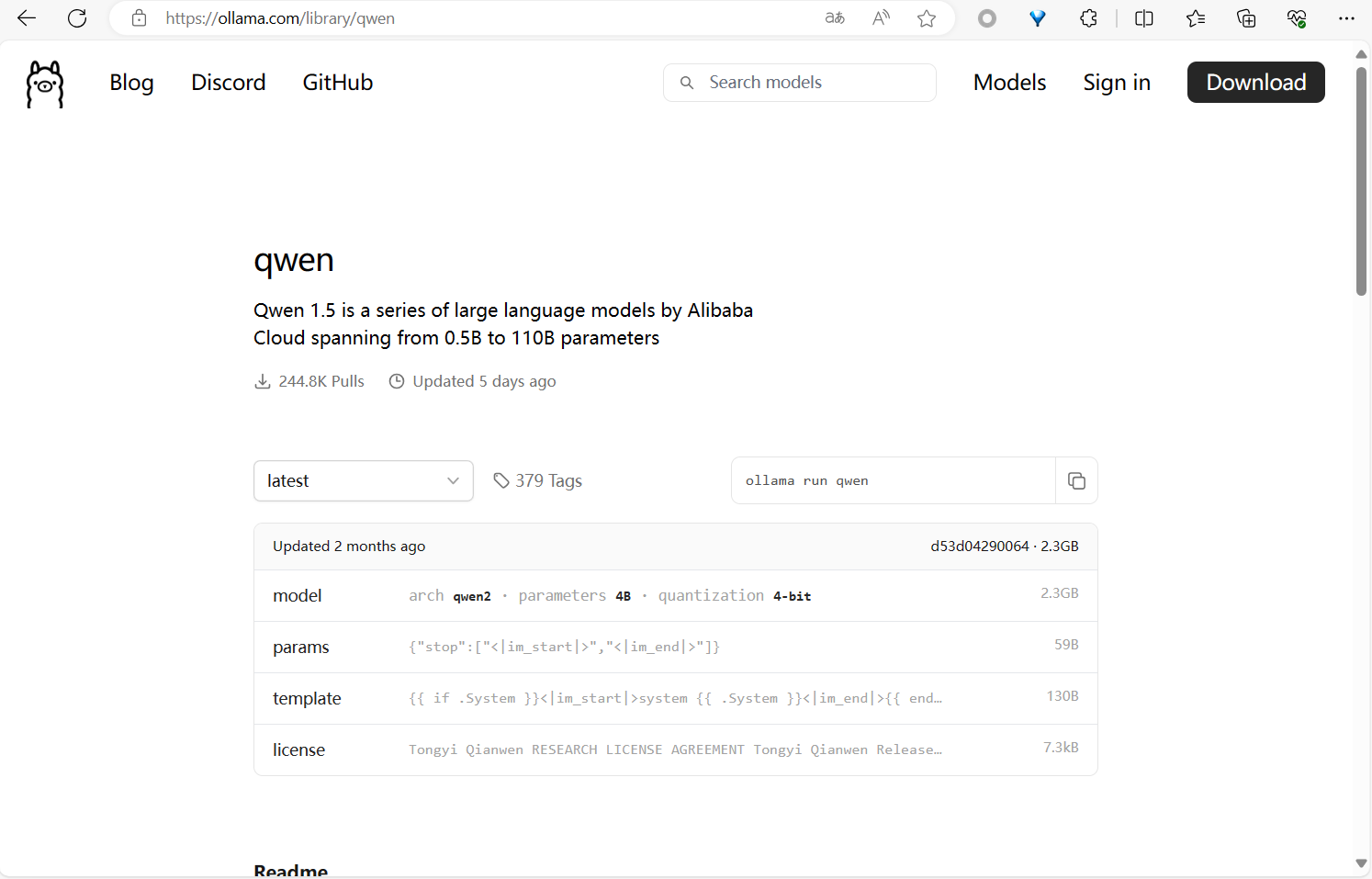
模型详情
使用
安装 Ollama 非常简单,直接参照官方文档就可完成。
Ollama 常用的几个CLI命令如下,这些API均有对应的WEB API形式,详见ollama/docs/api.md at main · ollama/ollama (github.com)。
ollama pull qwen,拉取模型latest版本(4b 4bit),支持指定不同的版本,如ollama pull qwen:1.8b。具体有哪些版本可以模型详情页面查看。ollama run qwen, 以对话的形式在命令行运行模型ollama run qwen "天空为什么是绿的?",使用大模型生成回答ollama server,运行ollama服务启动WEB API监听
注意,embedding 模型不支持通过命令行使用。
Ollama 运行后,默认会在本地 127.0.0.1:11434 地址监听web请求,如需支持外部机器访问,Windows需在系统高级设置中添加环境变量OLLAMA_HOST,Linux需为ollama.service添加环境变量。
# 文件 /etc/systemd/system/ollama.service
# ...
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/root/.nvm/versions/node/v19.8.1/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/snap/bin"
# 添加OLLAMA_HOST环境变量
Environment=OLLAMA_HOST=0.0.0.0:11434"
#...
模型文件体积大,可通过环境变量 OLLAMA_MODELS 指定模型存储路径。
UI
命令行与大模型交互非常不方便,无法发挥所有能力。现在有非常多的UI界面可供选择,安装也非常方便,安装后配置Ollama API即可使用。
我在windows上安装了客户端UI chatbox,在linux上使用容器的方案安装open-webui。
硬件要求
大模型发展非常的快,日新月异,每天都要被AI相关的信息轰炸!
目前大模型相关的生态已经很丰富,应用开发框架也有相当的成熟度,作为人个开发者开发自己的应用已经非常简单。大模型的“小型化”,让大模型在硬件配置更低的平台运行是一个趋势。大模型无法在个人电脑运行的观点,是时候更新了。
我的主力机是一台 5年前的联想笔记本,CPU i7-8750H,内存 24G 2667Mhz,显卡 GTX 1050 Ti 4G。显卡虽然弱鸡,但很幸运能支持CUDA11.1。由于我平时不咋玩游戏,显卡基本是摆设,现在能发光发热想必它会感到很高兴!
效果
以下记录部分模型运行效果,以4bit模型为主。
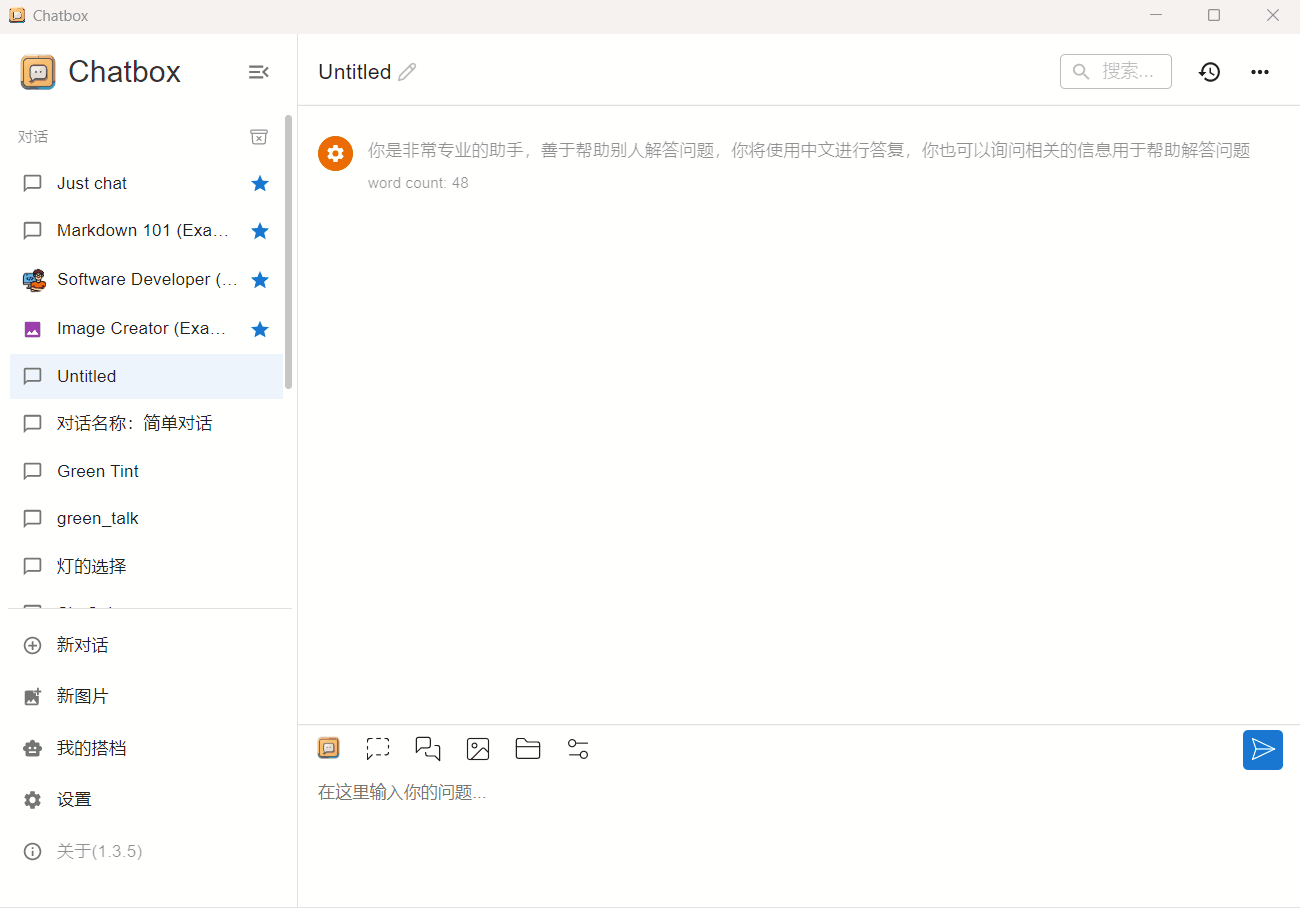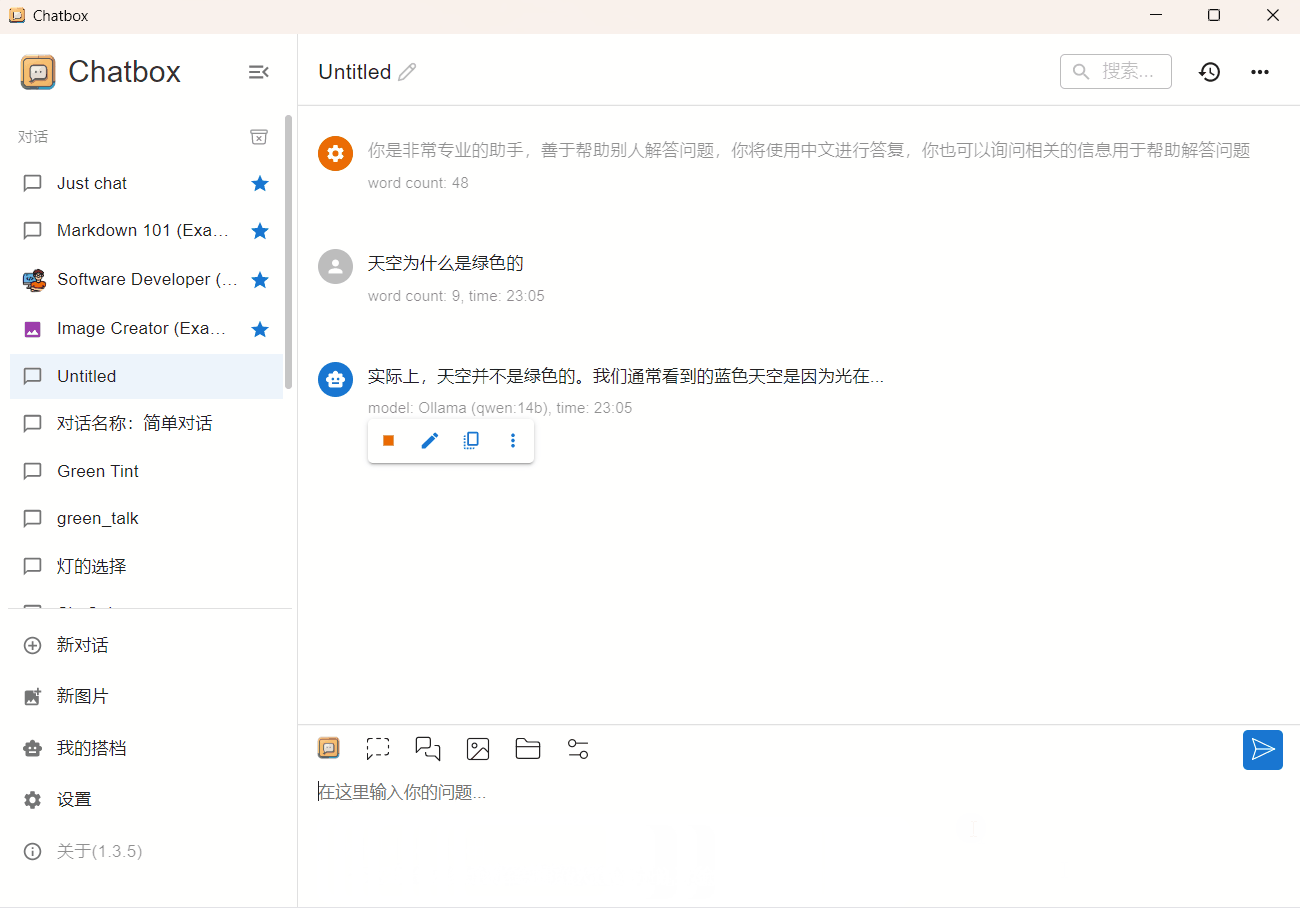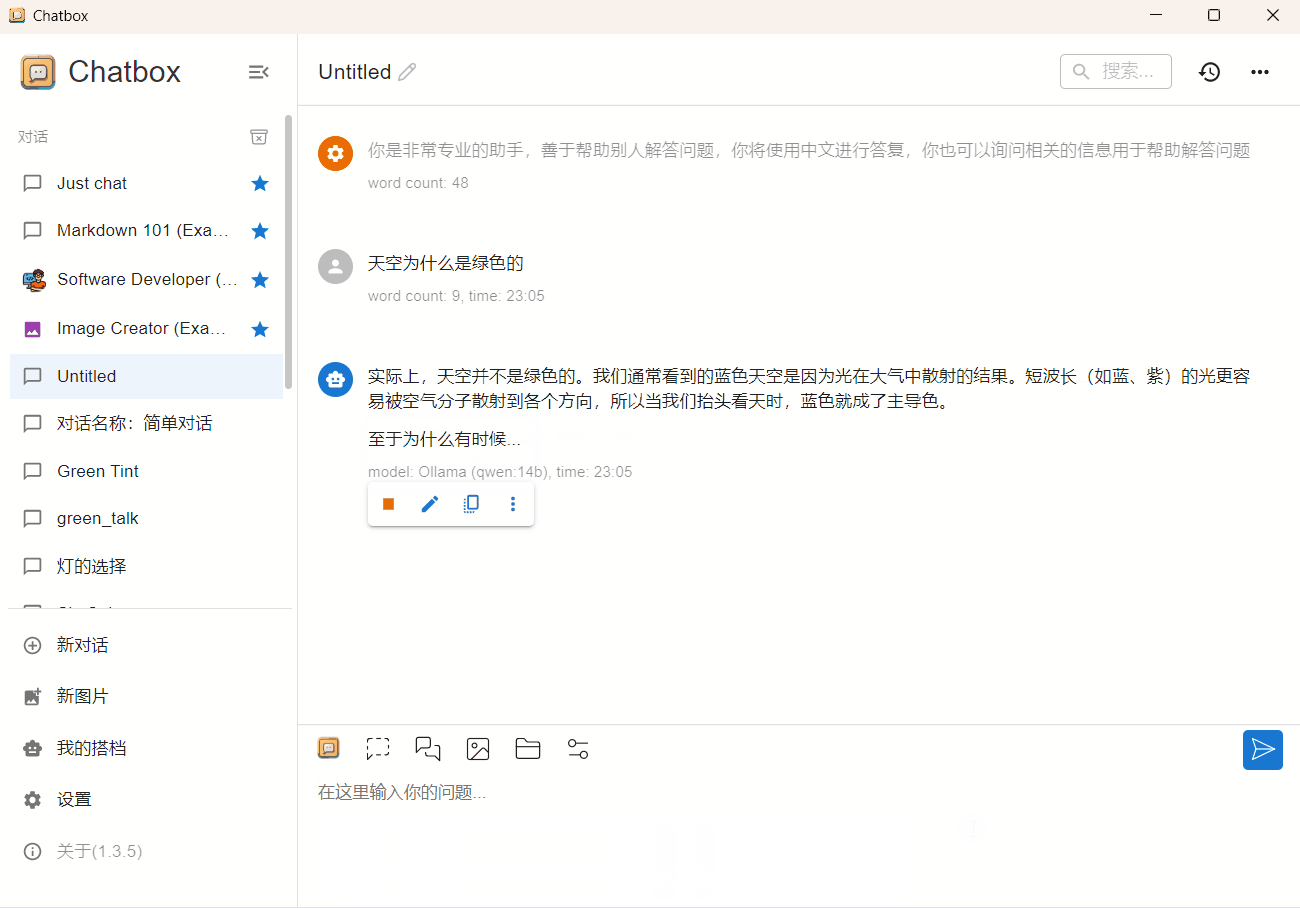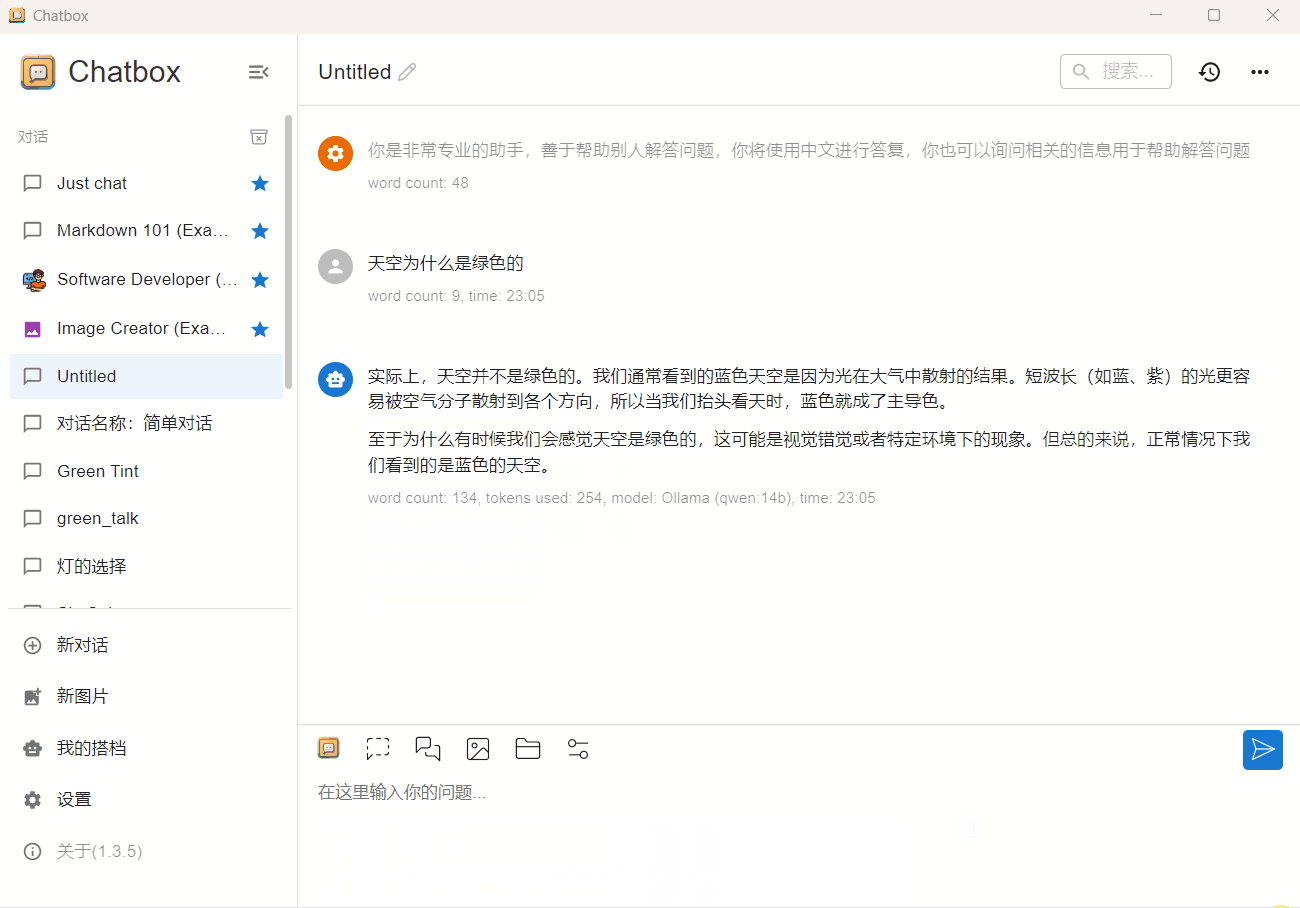
qwen 14b 4bit
CPU占用90%,内存占用13G(GPU+CPU),输出速度 2 token/s。更详细的内存分配信息可以查看查看Ollama日志文件。运行起来输出有点慢,需要一些耐心。
qwen 7b 4bit
CPU占用80%,内存占用8.1G(GPU+CPU),输出速度 5 token/s,对于问答任务,这个速度已经可以接受。
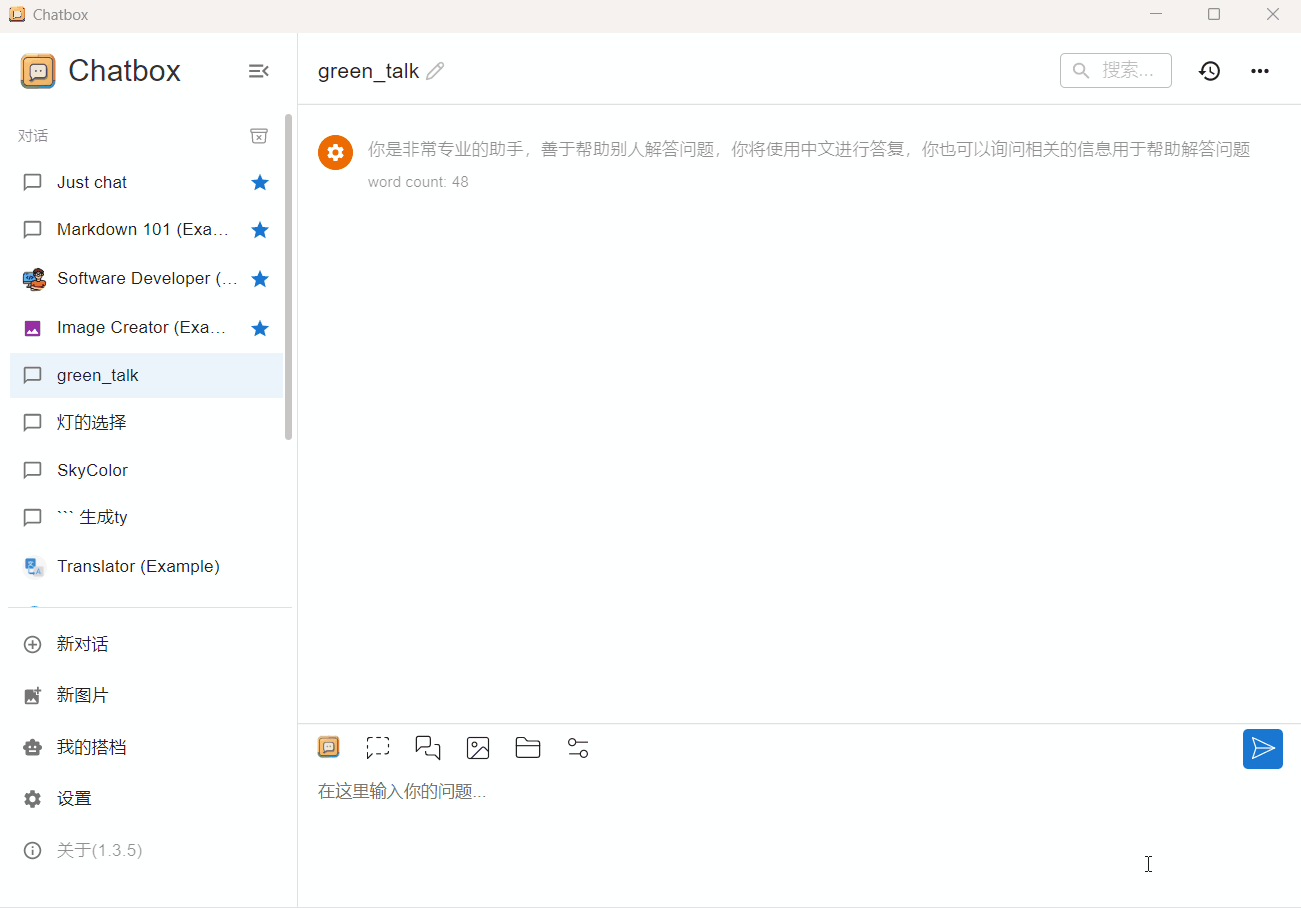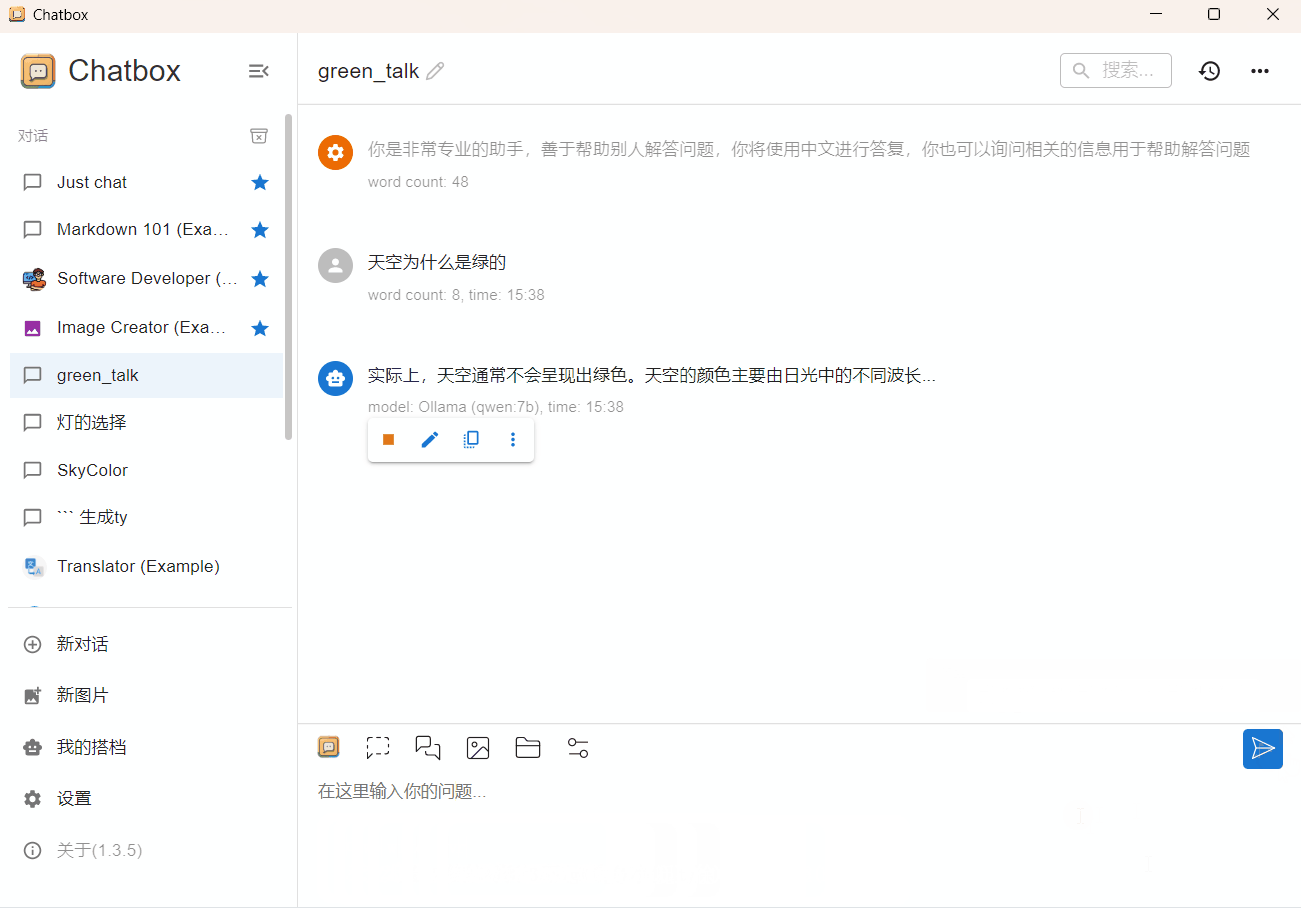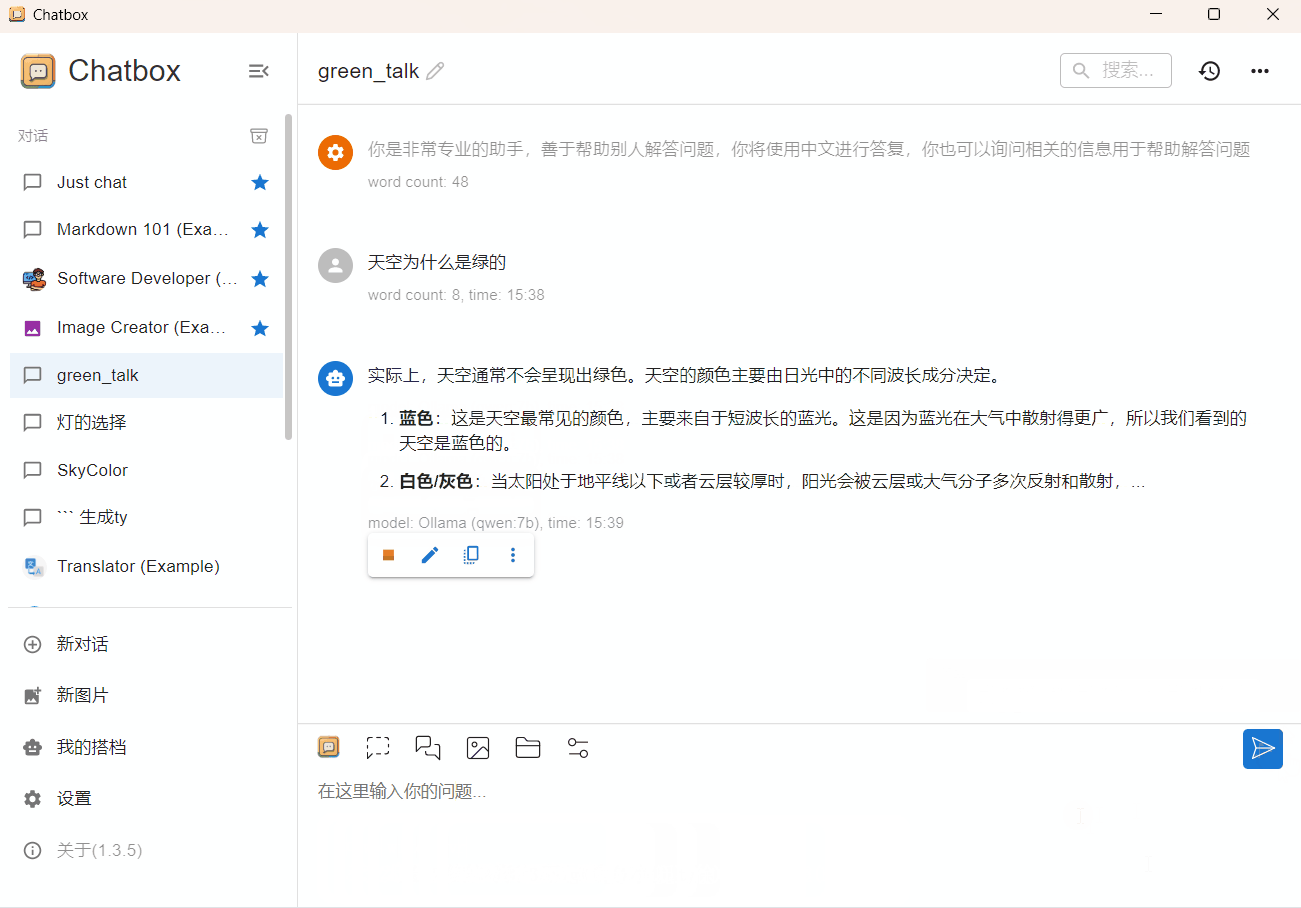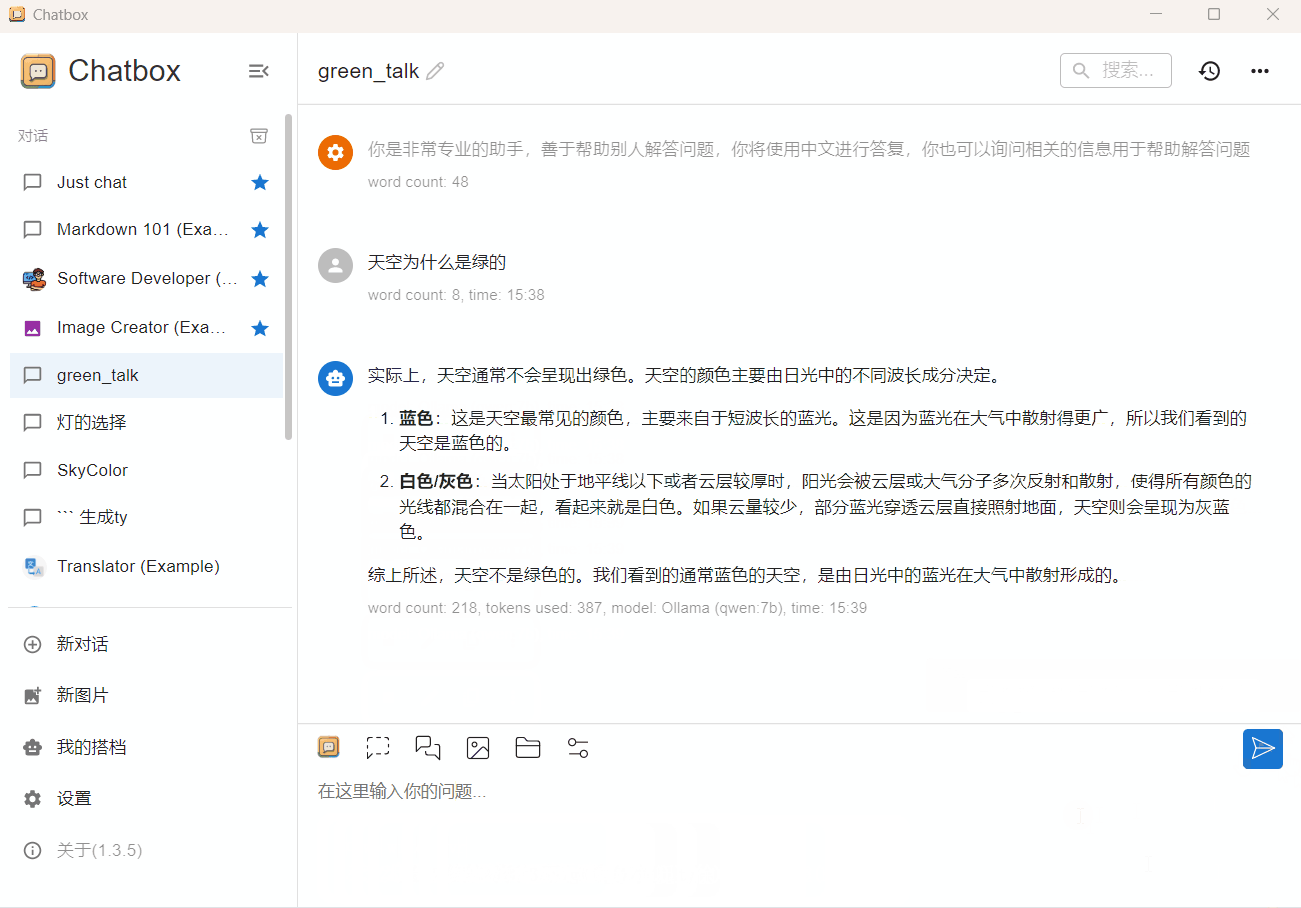
qwen 2b 4bit
基本不占用CPU,内存占用1.8G(GPU),输出速度 38token/s,输出速度直接起飞!但是答案对不对呢,希望有人可以告诉我。
bge-large-zh-v1.5-f16
embedding模型一般参数不大,中文效果较好的模型 bge-large-zh-v1.5-f16,参数324M,4G显卡跑32bit输出速度肯定没问题。我有个小主机,使用它运行f16模型试试效果,如果能顺畅运行,以后可以把embedding作为服务放到小主机运行。小主机分配Ollama 运行容器CPU为N5105 3 * 2GHz,内存4G,运行效果如下。
embed 一段文本, 293个中文字符,耗时1m44s。
embed 一个长句,38个中文字符,耗时16s。
embed 一个短句,简短的问题文本,10个中文字符,耗时3.3s。
可见,小主机的CPU性能太差。运行时CPU占用97%,内存占用370M。如果用来计算简短问题的embedding时间还可以接受,如果需要计算与其他embedding的相似度,总体耗时可能会很长。简单的说,用来运行RAG 处理embedding相关的部分可能不太现实,除非使用更低精度的模型,另外随着文档数量增加查询时间也会相应增加。
量化模型
模型量化 减少了运行模型的硬件要求,是普通个人主机运行模型的关键,但是量化同时会影响模型的效果。如果量化后模型准确度降得非常低,整天胡言乱语,那么个人主机即使能运行1000个模型也没意义。
目前来看,4bit是量化的底线,一但低于4bit模型就废了。根据了解到的信息,4bit模型基本保留了原有模型的能力,从16bit、8bit、到4bit,模型能力下降并不多,所以使用量化模型在本地折腾存在可行性。
总结
根据初步运行的结果,得出以下几个结论,不一定完全准确。
- 个人电脑配置(不低于上述配置)可以较流畅地运行7b 4bit模型,运行4b 4bit模型速度非常快
- llama3 对中文支持较差,使用中文回复会出现胡言乱语
- 与全精度模型相比,4bit模型可用,未发现明显问题
- 2b 4bit模型,偶尔出现胡言乱语,可用性存疑
相关资料